Natural Language Processing¶
!pip install tensorflow-hub
!pip install tensorflow-datasets
Requirement already satisfied: tensorflow-hub in /usr/local/lib/python3.10/dist-packages (0.16.1) Requirement already satisfied: numpy>=1.12.0 in /usr/local/lib/python3.10/dist-packages (from tensorflow-hub) (1.25.2) Requirement already satisfied: protobuf>=3.19.6 in /usr/local/lib/python3.10/dist-packages (from tensorflow-hub) (3.20.3) Requirement already satisfied: tf-keras>=2.14.1 in /usr/local/lib/python3.10/dist-packages (from tensorflow-hub) (2.15.0) Requirement already satisfied: tensorflow-datasets in /usr/local/lib/python3.10/dist-packages (4.9.4) Requirement already satisfied: absl-py in /usr/local/lib/python3.10/dist-packages (from tensorflow-datasets) (1.4.0) Requirement already satisfied: click in /usr/local/lib/python3.10/dist-packages (from tensorflow-datasets) (8.1.7) Requirement already satisfied: dm-tree in /usr/local/lib/python3.10/dist-packages (from tensorflow-datasets) (0.1.8) Requirement already satisfied: etils[enp,epath,etree]>=0.9.0 in /usr/local/lib/python3.10/dist-packages (from tensorflow-datasets) (1.7.0) Requirement already satisfied: numpy in /usr/local/lib/python3.10/dist-packages (from tensorflow-datasets) (1.25.2) Requirement already satisfied: promise in /usr/local/lib/python3.10/dist-packages (from tensorflow-datasets) (2.3) Requirement already satisfied: protobuf>=3.20 in /usr/local/lib/python3.10/dist-packages (from tensorflow-datasets) (3.20.3) Requirement already satisfied: psutil in /usr/local/lib/python3.10/dist-packages (from tensorflow-datasets) (5.9.5) Requirement already satisfied: requests>=2.19.0 in /usr/local/lib/python3.10/dist-packages (from tensorflow-datasets) (2.31.0) Requirement already satisfied: tensorflow-metadata in /usr/local/lib/python3.10/dist-packages (from tensorflow-datasets) (1.14.0) Requirement already satisfied: termcolor in /usr/local/lib/python3.10/dist-packages (from tensorflow-datasets) (2.4.0) Requirement already satisfied: toml in /usr/local/lib/python3.10/dist-packages (from tensorflow-datasets) (0.10.2) Requirement already satisfied: tqdm in /usr/local/lib/python3.10/dist-packages (from tensorflow-datasets) (4.66.2) Requirement already satisfied: wrapt in /usr/local/lib/python3.10/dist-packages (from tensorflow-datasets) (1.14.1) Requirement already satisfied: array-record>=0.5.0 in /usr/local/lib/python3.10/dist-packages (from tensorflow-datasets) (0.5.0) Requirement already satisfied: fsspec in /usr/local/lib/python3.10/dist-packages (from etils[enp,epath,etree]>=0.9.0->tensorflow-datasets) (2023.6.0) Requirement already satisfied: importlib_resources in /usr/local/lib/python3.10/dist-packages (from etils[enp,epath,etree]>=0.9.0->tensorflow-datasets) (6.1.2) Requirement already satisfied: typing_extensions in /usr/local/lib/python3.10/dist-packages (from etils[enp,epath,etree]>=0.9.0->tensorflow-datasets) (4.10.0) Requirement already satisfied: zipp in /usr/local/lib/python3.10/dist-packages (from etils[enp,epath,etree]>=0.9.0->tensorflow-datasets) (3.17.0) Requirement already satisfied: charset-normalizer<4,>=2 in /usr/local/lib/python3.10/dist-packages (from requests>=2.19.0->tensorflow-datasets) (3.3.2) Requirement already satisfied: idna<4,>=2.5 in /usr/local/lib/python3.10/dist-packages (from requests>=2.19.0->tensorflow-datasets) (3.6) Requirement already satisfied: urllib3<3,>=1.21.1 in /usr/local/lib/python3.10/dist-packages (from requests>=2.19.0->tensorflow-datasets) (2.0.7) Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.10/dist-packages (from requests>=2.19.0->tensorflow-datasets) (2024.2.2) Requirement already satisfied: six in /usr/local/lib/python3.10/dist-packages (from promise->tensorflow-datasets) (1.16.0) Requirement already satisfied: googleapis-common-protos<2,>=1.52.0 in /usr/local/lib/python3.10/dist-packages (from tensorflow-metadata->tensorflow-datasets) (1.62.0)
import os
import numpy as np
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_datasets as tfds
Natural Language Processing¶
1. Text Pre-processing¶
1.1 Loading the Dataset¶
tfds.list_builders()
['abstract_reasoning', 'accentdb', 'aeslc', 'aflw2k3d', 'ag_news_subset', 'ai2_arc', 'ai2_arc_with_ir', 'amazon_us_reviews', 'anli', 'answer_equivalence', 'arc', 'asqa', 'asset', 'assin2', 'asu_table_top_converted_externally_to_rlds', 'austin_buds_dataset_converted_externally_to_rlds', 'austin_sailor_dataset_converted_externally_to_rlds', 'austin_sirius_dataset_converted_externally_to_rlds', 'bair_robot_pushing_small', 'bc_z', 'bccd', 'beans', 'bee_dataset', 'beir', 'berkeley_autolab_ur5', 'berkeley_cable_routing', 'berkeley_fanuc_manipulation', 'berkeley_gnm_cory_hall', 'berkeley_gnm_recon', 'berkeley_gnm_sac_son', 'berkeley_mvp_converted_externally_to_rlds', 'berkeley_rpt_converted_externally_to_rlds', 'big_patent', 'bigearthnet', 'billsum', 'binarized_mnist', 'binary_alpha_digits', 'ble_wind_field', 'blimp', 'booksum', 'bool_q', 'bot_adversarial_dialogue', 'bridge', 'bucc', 'c4', 'c4_wsrs', 'caltech101', 'caltech_birds2010', 'caltech_birds2011', 'cardiotox', 'cars196', 'cassava', 'cats_vs_dogs', 'celeb_a', 'celeb_a_hq', 'cfq', 'cherry_blossoms', 'chexpert', 'cifar10', 'cifar100', 'cifar100_n', 'cifar10_1', 'cifar10_corrupted', 'cifar10_h', 'cifar10_n', 'citrus_leaves', 'cityscapes', 'civil_comments', 'clevr', 'clic', 'clinc_oos', 'cmaterdb', 'cmu_franka_exploration_dataset_converted_externally_to_rlds', 'cmu_play_fusion', 'cmu_stretch', 'cnn_dailymail', 'coco', 'coco_captions', 'coil100', 'colorectal_histology', 'colorectal_histology_large', 'columbia_cairlab_pusht_real', 'common_voice', 'conll2002', 'conll2003', 'controlled_noisy_web_labels', 'coqa', 'corr2cause', 'cos_e', 'cosmos_qa', 'covid19', 'covid19sum', 'crema_d', 'criteo', 'cs_restaurants', 'curated_breast_imaging_ddsm', 'cycle_gan', 'd4rl_adroit_door', 'd4rl_adroit_hammer', 'd4rl_adroit_pen', 'd4rl_adroit_relocate', 'd4rl_antmaze', 'd4rl_mujoco_ant', 'd4rl_mujoco_halfcheetah', 'd4rl_mujoco_hopper', 'd4rl_mujoco_walker2d', 'dart', 'databricks_dolly', 'davis', 'deep1b', 'deep_weeds', 'definite_pronoun_resolution', 'dementiabank', 'diabetic_retinopathy_detection', 'diamonds', 'div2k', 'dlr_edan_shared_control_converted_externally_to_rlds', 'dlr_sara_grid_clamp_converted_externally_to_rlds', 'dlr_sara_pour_converted_externally_to_rlds', 'dmlab', 'doc_nli', 'dolphin_number_word', 'domainnet', 'downsampled_imagenet', 'drop', 'dsprites', 'dtd', 'duke_ultrasound', 'e2e_cleaned', 'efron_morris75', 'emnist', 'eraser_multi_rc', 'esnli', 'eth_agent_affordances', 'eurosat', 'fashion_mnist', 'flic', 'flores', 'food101', 'forest_fires', 'fractal20220817_data', 'fuss', 'gap', 'geirhos_conflict_stimuli', 'gem', 'genomics_ood', 'german_credit_numeric', 'gigaword', 'glove100_angular', 'glue', 'goemotions', 'gov_report', 'gpt3', 'gref', 'groove', 'grounded_scan', 'gsm8k', 'gtzan', 'gtzan_music_speech', 'hellaswag', 'higgs', 'hillstrom', 'horses_or_humans', 'howell', 'i_naturalist2017', 'i_naturalist2018', 'i_naturalist2021', 'iamlab_cmu_pickup_insert_converted_externally_to_rlds', 'imagenet2012', 'imagenet2012_corrupted', 'imagenet2012_fewshot', 'imagenet2012_multilabel', 'imagenet2012_real', 'imagenet2012_subset', 'imagenet_a', 'imagenet_lt', 'imagenet_pi', 'imagenet_r', 'imagenet_resized', 'imagenet_sketch', 'imagenet_v2', 'imagenette', 'imagewang', 'imdb_reviews', 'imperialcollege_sawyer_wrist_cam', 'irc_disentanglement', 'iris', 'istella', 'jaco_play', 'kaist_nonprehensile_converted_externally_to_rlds', 'kddcup99', 'kitti', 'kmnist', 'kuka', 'laion400m', 'lambada', 'lfw', 'librispeech', 'librispeech_lm', 'libritts', 'ljspeech', 'lm1b', 'locomotion', 'lost_and_found', 'lsun', 'lvis', 'malaria', 'maniskill_dataset_converted_externally_to_rlds', 'math_dataset', 'math_qa', 'mctaco', 'media_sum', 'mlqa', 'mnist', 'mnist_corrupted', 'movie_lens', 'movie_rationales', 'movielens', 'moving_mnist', 'mrqa', 'mslr_web', 'mt_opt', 'mtnt', 'multi_news', 'multi_nli', 'multi_nli_mismatch', 'natural_instructions', 'natural_questions', 'natural_questions_open', 'newsroom', 'nsynth', 'nyu_depth_v2', 'nyu_door_opening_surprising_effectiveness', 'nyu_franka_play_dataset_converted_externally_to_rlds', 'nyu_rot_dataset_converted_externally_to_rlds', 'ogbg_molpcba', 'omniglot', 'open_images_challenge2019_detection', 'open_images_v4', 'openbookqa', 'opinion_abstracts', 'opinosis', 'opus', 'oxford_flowers102', 'oxford_iiit_pet', 'para_crawl', 'pass', 'patch_camelyon', 'paws_wiki', 'paws_x_wiki', 'penguins', 'pet_finder', 'pg19', 'piqa', 'places365_small', 'placesfull', 'plant_leaves', 'plant_village', 'plantae_k', 'protein_net', 'q_re_cc', 'qa4mre', 'qasc', 'quac', 'quality', 'quickdraw_bitmap', 'race', 'radon', 'real_toxicity_prompts', 'reddit', 'reddit_disentanglement', 'reddit_tifu', 'ref_coco', 'resisc45', 'rlu_atari', 'rlu_atari_checkpoints', 'rlu_atari_checkpoints_ordered', 'rlu_control_suite', 'rlu_dmlab_explore_object_rewards_few', 'rlu_dmlab_explore_object_rewards_many', 'rlu_dmlab_rooms_select_nonmatching_object', 'rlu_dmlab_rooms_watermaze', 'rlu_dmlab_seekavoid_arena01', 'rlu_locomotion', 'rlu_rwrl', 'robomimic_mg', 'robomimic_mh', 'robomimic_ph', 'robonet', 'robosuite_panda_pick_place_can', 'roboturk', 'rock_paper_scissors', 'rock_you', 's3o4d', 'salient_span_wikipedia', 'samsum', 'savee', 'scan', 'scene_parse150', 'schema_guided_dialogue', 'sci_tail', 'scicite', 'scientific_papers', 'scrolls', 'segment_anything', 'sentiment140', 'shapes3d', 'sift1m', 'simpte', 'siscore', 'smallnorb', 'smartwatch_gestures', 'snli', 'so2sat', 'speech_commands', 'spoken_digit', 'squad', 'squad_question_generation', 'stanford_dogs', 'stanford_hydra_dataset_converted_externally_to_rlds', 'stanford_kuka_multimodal_dataset_converted_externally_to_rlds', 'stanford_mask_vit_converted_externally_to_rlds', 'stanford_online_products', 'stanford_robocook_converted_externally_to_rlds', 'star_cfq', 'starcraft_video', 'stl10', 'story_cloze', 'summscreen', 'sun397', 'super_glue', 'svhn_cropped', 'symmetric_solids', 'taco_play', 'tao', 'tatoeba', 'ted_hrlr_translate', 'ted_multi_translate', 'tedlium', 'tf_flowers', 'the300w_lp', 'tiny_shakespeare', 'titanic', 'tokyo_u_lsmo_converted_externally_to_rlds', 'toto', 'trec', 'trivia_qa', 'tydi_qa', 'uc_merced', 'ucf101', 'ucsd_kitchen_dataset_converted_externally_to_rlds', 'ucsd_pick_and_place_dataset_converted_externally_to_rlds', 'uiuc_d3field', 'unified_qa', 'universal_dependencies', 'unnatural_instructions', 'usc_cloth_sim_converted_externally_to_rlds', 'user_libri_audio', 'user_libri_text', 'utaustin_mutex', 'utokyo_pr2_opening_fridge_converted_externally_to_rlds', 'utokyo_pr2_tabletop_manipulation_converted_externally_to_rlds', 'utokyo_saytap_converted_externally_to_rlds', 'utokyo_xarm_bimanual_converted_externally_to_rlds', 'utokyo_xarm_pick_and_place_converted_externally_to_rlds', 'vctk', 'viola', 'visual_domain_decathlon', 'voc', 'voxceleb', 'voxforge', 'waymo_open_dataset', 'web_graph', 'web_nlg', 'web_questions', 'webvid', 'wider_face', 'wiki40b', 'wiki_auto', 'wiki_bio', 'wiki_dialog', 'wiki_table_questions', 'wiki_table_text', 'wikiann', 'wikihow', 'wikipedia', 'wikipedia_toxicity_subtypes', 'wine_quality', 'winogrande', 'wit', 'wit_kaggle', 'wmt13_translate', 'wmt14_translate', 'wmt15_translate', 'wmt16_translate', 'wmt17_translate', 'wmt18_translate', 'wmt19_translate', 'wmt_t2t_translate', 'wmt_translate', 'wordnet', 'wsc273', 'xnli', 'xquad', 'xsum', 'xtreme_pawsx', 'xtreme_pos', 'xtreme_s', 'xtreme_xnli', 'yahoo_ltrc', 'yelp_polarity_reviews', 'yes_no', 'youtube_vis', 'huggingface:acronym_identification', 'huggingface:ade_corpus_v2', 'huggingface:adv_glue', 'huggingface:adversarial_qa', 'huggingface:aeslc', 'huggingface:afrikaans_ner_corpus', 'huggingface:ag_news', 'huggingface:ai2_arc', 'huggingface:air_dialogue', 'huggingface:ajgt_twitter_ar', 'huggingface:allegro_reviews', 'huggingface:allocine', 'huggingface:alt', 'huggingface:amazon_polarity', 'huggingface:amazon_reviews_multi', 'huggingface:amazon_us_reviews', 'huggingface:ambig_qa', 'huggingface:americas_nli', 'huggingface:ami', 'huggingface:amttl', 'huggingface:anli', 'huggingface:app_reviews', 'huggingface:aqua_rat', 'huggingface:aquamuse', 'huggingface:ar_cov19', 'huggingface:ar_res_reviews', 'huggingface:ar_sarcasm', 'huggingface:arabic_billion_words', 'huggingface:arabic_pos_dialect', 'huggingface:arabic_speech_corpus', 'huggingface:arcd', 'huggingface:arsentd_lev', 'huggingface:art', 'huggingface:arxiv_dataset', 'huggingface:ascent_kb', 'huggingface:aslg_pc12', 'huggingface:asnq', 'huggingface:asset', 'huggingface:assin', 'huggingface:assin2', 'huggingface:atomic', 'huggingface:autshumato', 'huggingface:babi_qa', 'huggingface:banking77', 'huggingface:bbaw_egyptian', 'huggingface:bbc_hindi_nli', 'huggingface:bc2gm_corpus', 'huggingface:beans', 'huggingface:best2009', 'huggingface:bianet', 'huggingface:bible_para', 'huggingface:big_patent', 'huggingface:bigbench', 'huggingface:billsum', 'huggingface:bing_coronavirus_query_set', 'huggingface:biomrc', 'huggingface:biosses', 'huggingface:biwi_kinect_head_pose', 'huggingface:blbooks', 'huggingface:blbooksgenre', 'huggingface:blended_skill_talk', 'huggingface:blimp', 'huggingface:blog_authorship_corpus', 'huggingface:bn_hate_speech', 'huggingface:bnl_newspapers', 'huggingface:bookcorpus', 'huggingface:bookcorpusopen', 'huggingface:boolq', 'huggingface:bprec', 'huggingface:break_data', 'huggingface:brwac', 'huggingface:bsd_ja_en', 'huggingface:bswac', 'huggingface:c3', 'huggingface:c4', 'huggingface:cail2018', 'huggingface:caner', 'huggingface:capes', 'huggingface:casino', 'huggingface:catalonia_independence', 'huggingface:cats_vs_dogs', 'huggingface:cawac', 'huggingface:cbt', 'huggingface:cc100', 'huggingface:cc_news', 'huggingface:ccaligned_multilingual', 'huggingface:cdsc', 'huggingface:cdt', 'huggingface:cedr', 'huggingface:cfq', 'huggingface:chr_en', 'huggingface:cifar10', 'huggingface:cifar100', 'huggingface:circa', 'huggingface:civil_comments', 'huggingface:clickbait_news_bg', 'huggingface:climate_fever', 'huggingface:clinc_oos', 'huggingface:clue', 'huggingface:cmrc2018', 'huggingface:cmu_hinglish_dog', 'huggingface:cnn_dailymail', 'huggingface:coached_conv_pref', 'huggingface:coarse_discourse', 'huggingface:codah', 'huggingface:code_search_net', 'huggingface:code_x_glue_cc_clone_detection_big_clone_bench', 'huggingface:code_x_glue_cc_clone_detection_poj104', 'huggingface:code_x_glue_cc_cloze_testing_all', 'huggingface:code_x_glue_cc_cloze_testing_maxmin', 'huggingface:code_x_glue_cc_code_completion_line', 'huggingface:code_x_glue_cc_code_completion_token', 'huggingface:code_x_glue_cc_code_refinement', 'huggingface:code_x_glue_cc_code_to_code_trans', 'huggingface:code_x_glue_cc_defect_detection', 'huggingface:code_x_glue_ct_code_to_text', 'huggingface:code_x_glue_tc_nl_code_search_adv', 'huggingface:code_x_glue_tc_text_to_code', 'huggingface:code_x_glue_tt_text_to_text', 'huggingface:com_qa', 'huggingface:common_gen', 'huggingface:common_language', 'huggingface:common_voice', 'huggingface:commonsense_qa', 'huggingface:competition_math', 'huggingface:compguesswhat', 'huggingface:conceptnet5', 'huggingface:conceptual_12m', 'huggingface:conceptual_captions', 'huggingface:conll2000', 'huggingface:conll2002', 'huggingface:conll2003', 'huggingface:conll2012_ontonotesv5', 'huggingface:conllpp', 'huggingface:consumer-finance-complaints', 'huggingface:conv_ai', 'huggingface:conv_ai_2', 'huggingface:conv_ai_3', 'huggingface:conv_questions', 'huggingface:coqa', 'huggingface:cord19', 'huggingface:cornell_movie_dialog', 'huggingface:cos_e', 'huggingface:cosmos_qa', 'huggingface:counter', 'huggingface:covid_qa_castorini', 'huggingface:covid_qa_deepset', 'huggingface:covid_qa_ucsd', 'huggingface:covid_tweets_japanese', 'huggingface:covost2', 'huggingface:cppe-5', 'huggingface:craigslist_bargains', 'huggingface:crawl_domain', 'huggingface:crd3', 'huggingface:crime_and_punish', 'huggingface:crows_pairs', 'huggingface:cryptonite', 'huggingface:cs_restaurants', 'huggingface:cuad', 'huggingface:curiosity_dialogs', 'huggingface:daily_dialog', 'huggingface:dane', 'huggingface:danish_political_comments', 'huggingface:dart', 'huggingface:datacommons_factcheck', 'huggingface:dbpedia_14', 'huggingface:dbrd', 'huggingface:deal_or_no_dialog', 'huggingface:definite_pronoun_resolution', 'huggingface:dengue_filipino', 'huggingface:dialog_re', 'huggingface:diplomacy_detection', 'huggingface:disaster_response_messages', 'huggingface:discofuse', 'huggingface:discovery', 'huggingface:disfl_qa', 'huggingface:doc2dial', 'huggingface:docred', 'huggingface:doqa', 'huggingface:dream', 'huggingface:drop', 'huggingface:duorc', 'huggingface:dutch_social', 'huggingface:dyk', 'huggingface:e2e_nlg', 'huggingface:e2e_nlg_cleaned', 'huggingface:ecb', 'huggingface:ecthr_cases', 'huggingface:eduge', 'huggingface:ehealth_kd', 'huggingface:eitb_parcc', 'huggingface:electricity_load_diagrams', 'huggingface:eli5', 'huggingface:eli5_category', 'huggingface:elkarhizketak', 'huggingface:emea', 'huggingface:emo', 'huggingface:emotion', 'huggingface:emotone_ar', 'huggingface:empathetic_dialogues', 'huggingface:enriched_web_nlg', 'huggingface:enwik8', 'huggingface:eraser_multi_rc', 'huggingface:esnli', 'huggingface:eth_py150_open', 'huggingface:ethos', 'huggingface:ett', 'huggingface:eu_regulatory_ir', 'huggingface:eurlex', 'huggingface:euronews', 'huggingface:europa_eac_tm', 'huggingface:europa_ecdc_tm', 'huggingface:europarl_bilingual', 'huggingface:event2Mind', 'huggingface:evidence_infer_treatment', 'huggingface:exams', 'huggingface:factckbr', 'huggingface:fake_news_english', 'huggingface:fake_news_filipino', 'huggingface:farsi_news', 'huggingface:fashion_mnist', 'huggingface:fever', 'huggingface:few_rel', 'huggingface:financial_phrasebank', 'huggingface:finer', 'huggingface:flores', 'huggingface:flue', 'huggingface:food101', 'huggingface:fquad', 'huggingface:freebase_qa', 'huggingface:gap', 'huggingface:gem', 'huggingface:generated_reviews_enth', 'huggingface:generics_kb', 'huggingface:german_legal_entity_recognition', 'huggingface:germaner', 'huggingface:germeval_14', 'huggingface:giga_fren', 'huggingface:gigaword', 'huggingface:glucose', 'huggingface:glue', 'huggingface:gnad10', 'huggingface:go_emotions', 'huggingface:gooaq', 'huggingface:google_wellformed_query', 'huggingface:grail_qa', 'huggingface:great_code', 'huggingface:greek_legal_code', 'huggingface:gsm8k', 'huggingface:guardian_authorship', 'huggingface:gutenberg_time', 'huggingface:hans', 'huggingface:hansards', 'huggingface:hard', 'huggingface:harem', 'huggingface:has_part', 'huggingface:hate_offensive', 'huggingface:hate_speech18', 'huggingface:hate_speech_filipino', 'huggingface:hate_speech_offensive', 'huggingface:hate_speech_pl', 'huggingface:hate_speech_portuguese', 'huggingface:hatexplain', 'huggingface:hausa_voa_ner', 'huggingface:hausa_voa_topics', 'huggingface:hda_nli_hindi', 'huggingface:head_qa', 'huggingface:health_fact', 'huggingface:hebrew_projectbenyehuda', 'huggingface:hebrew_sentiment', 'huggingface:hebrew_this_world', 'huggingface:hellaswag', 'huggingface:hendrycks_test', 'huggingface:hind_encorp', 'huggingface:hindi_discourse', 'huggingface:hippocorpus', 'huggingface:hkcancor', 'huggingface:hlgd', 'huggingface:hope_edi', 'huggingface:hotpot_qa', 'huggingface:hover', 'huggingface:hrenwac_para', 'huggingface:hrwac', 'huggingface:humicroedit', 'huggingface:hybrid_qa', 'huggingface:hyperpartisan_news_detection', 'huggingface:iapp_wiki_qa_squad', 'huggingface:id_clickbait', 'huggingface:id_liputan6', 'huggingface:id_nergrit_corpus', 'huggingface:id_newspapers_2018', 'huggingface:id_panl_bppt', 'huggingface:id_puisi', 'huggingface:igbo_english_machine_translation', 'huggingface:igbo_monolingual', 'huggingface:igbo_ner', 'huggingface:ilist', 'huggingface:imagenet-1k', 'huggingface:imagenet_sketch', 'huggingface:imdb', 'huggingface:imdb_urdu_reviews', 'huggingface:imppres', 'huggingface:indic_glue', 'huggingface:indonli', 'huggingface:indonlu', 'huggingface:inquisitive_qg', 'huggingface:interpress_news_category_tr', 'huggingface:interpress_news_category_tr_lite', 'huggingface:irc_disentangle', 'huggingface:isixhosa_ner_corpus', 'huggingface:isizulu_ner_corpus', 'huggingface:iwslt2017', 'huggingface:jeopardy', 'huggingface:jfleg', 'huggingface:jigsaw_toxicity_pred', 'huggingface:jigsaw_unintended_bias', 'huggingface:jnlpba', 'huggingface:journalists_questions', 'huggingface:kan_hope', 'huggingface:kannada_news', 'huggingface:kd_conv', 'huggingface:kde4', 'huggingface:kelm', 'huggingface:kilt_tasks', 'huggingface:kilt_wikipedia', 'huggingface:kinnews_kirnews', 'huggingface:klue', 'huggingface:kor_3i4k', 'huggingface:kor_hate', 'huggingface:kor_ner', 'huggingface:kor_nli', 'huggingface:kor_nlu', 'huggingface:kor_qpair', 'huggingface:kor_sae', 'huggingface:kor_sarcasm', 'huggingface:labr', 'huggingface:lama', 'huggingface:lambada', 'huggingface:large_spanish_corpus', 'huggingface:laroseda', 'huggingface:lc_quad', 'huggingface:lccc', 'huggingface:lener_br', 'huggingface:lex_glue', 'huggingface:liar', 'huggingface:librispeech_asr', 'huggingface:librispeech_lm', 'huggingface:limit', 'huggingface:lince', 'huggingface:linnaeus', 'huggingface:liveqa', 'huggingface:lj_speech', 'huggingface:lm1b', 'huggingface:lst20', 'huggingface:m_lama', 'huggingface:mac_morpho', 'huggingface:makhzan', 'huggingface:masakhaner', 'huggingface:math_dataset', 'huggingface:math_qa', 'huggingface:matinf', 'huggingface:mbpp', 'huggingface:mc4', 'huggingface:mc_taco', 'huggingface:md_gender_bias', 'huggingface:mdd', 'huggingface:med_hop', 'huggingface:medal', 'huggingface:medical_dialog', 'huggingface:medical_questions_pairs', 'huggingface:medmcqa', 'huggingface:menyo20k_mt', 'huggingface:meta_woz', 'huggingface:metashift', 'huggingface:metooma', 'huggingface:metrec', 'huggingface:miam', 'huggingface:mkb', 'huggingface:mkqa', 'huggingface:mlqa', 'huggingface:mlsum', 'huggingface:mnist', 'huggingface:mocha', 'huggingface:monash_tsf', 'huggingface:moroco', 'huggingface:movie_rationales', 'huggingface:mrqa', 'huggingface:ms_marco', 'huggingface:ms_terms', 'huggingface:msr_genomics_kbcomp', 'huggingface:msr_sqa', 'huggingface:msr_text_compression', 'huggingface:msr_zhen_translation_parity', 'huggingface:msra_ner', 'huggingface:mt_eng_vietnamese', 'huggingface:muchocine', 'huggingface:multi_booked', 'huggingface:multi_eurlex', 'huggingface:multi_news', 'huggingface:multi_nli', 'huggingface:multi_nli_mismatch', 'huggingface:multi_para_crawl', 'huggingface:multi_re_qa', 'huggingface:multi_woz_v22', 'huggingface:multi_x_science_sum', 'huggingface:multidoc2dial', 'huggingface:multilingual_librispeech', 'huggingface:mutual_friends', 'huggingface:mwsc', 'huggingface:myanmar_news', 'huggingface:narrativeqa', 'huggingface:narrativeqa_manual', 'huggingface:natural_questions', 'huggingface:ncbi_disease', 'huggingface:nchlt', 'huggingface:ncslgr', 'huggingface:nell', 'huggingface:neural_code_search', 'huggingface:news_commentary', 'huggingface:newsgroup', 'huggingface:newsph', 'huggingface:newsph_nli', 'huggingface:newspop', 'huggingface:newsqa', 'huggingface:newsroom', 'huggingface:nkjp-ner', 'huggingface:nli_tr', 'huggingface:nlu_evaluation_data', 'huggingface:norec', 'huggingface:norne', 'huggingface:norwegian_ner', 'huggingface:nq_open', 'huggingface:nsmc', 'huggingface:numer_sense', 'huggingface:numeric_fused_head', 'huggingface:oclar', 'huggingface:offcombr', 'huggingface:offenseval2020_tr', 'huggingface:offenseval_dravidian', 'huggingface:ofis_publik', 'huggingface:ohsumed', 'huggingface:ollie', 'huggingface:omp', 'huggingface:onestop_english', 'huggingface:onestop_qa', 'huggingface:open_subtitles', 'huggingface:openai_humaneval', 'huggingface:openbookqa', 'huggingface:openslr', 'huggingface:openwebtext', 'huggingface:opinosis', 'huggingface:opus100', 'huggingface:opus_books', 'huggingface:opus_dgt', 'huggingface:opus_dogc', 'huggingface:opus_elhuyar', 'huggingface:opus_euconst', 'huggingface:opus_finlex', 'huggingface:opus_fiskmo', 'huggingface:opus_gnome', 'huggingface:opus_infopankki', 'huggingface:opus_memat', 'huggingface:opus_montenegrinsubs', 'huggingface:opus_openoffice', 'huggingface:opus_paracrawl', 'huggingface:opus_rf', 'huggingface:opus_tedtalks', 'huggingface:opus_ubuntu', 'huggingface:opus_wikipedia', 'huggingface:opus_xhosanavy', 'huggingface:orange_sum', 'huggingface:oscar', 'huggingface:para_crawl', 'huggingface:para_pat', 'huggingface:parsinlu_reading_comprehension', 'huggingface:pass', 'huggingface:paws', 'huggingface:paws-x', 'huggingface:pec', 'huggingface:peer_read', 'huggingface:peoples_daily_ner', 'huggingface:per_sent', 'huggingface:persian_ner', 'huggingface:pg19', 'huggingface:php', 'huggingface:piaf', 'huggingface:pib', 'huggingface:piqa', 'huggingface:pn_summary', 'huggingface:poem_sentiment', 'huggingface:polemo2', 'huggingface:poleval2019_cyberbullying', 'huggingface:poleval2019_mt', 'huggingface:polsum', 'huggingface:polyglot_ner', 'huggingface:prachathai67k', 'huggingface:pragmeval', 'huggingface:proto_qa', 'huggingface:psc', 'huggingface:ptb_text_only', 'huggingface:pubmed', 'huggingface:pubmed_qa', 'huggingface:py_ast', 'huggingface:qa4mre', 'huggingface:qa_srl', 'huggingface:qa_zre', 'huggingface:qangaroo', 'huggingface:qanta', 'huggingface:qasc', 'huggingface:qasper', 'huggingface:qed', 'huggingface:qed_amara', 'huggingface:quac', 'huggingface:quail', 'huggingface:quarel', 'huggingface:quartz', 'huggingface:quickdraw', 'huggingface:quora', 'huggingface:quoref', 'huggingface:race', 'huggingface:re_dial', 'huggingface:reasoning_bg', 'huggingface:recipe_nlg', 'huggingface:reclor', 'huggingface:red_caps', 'huggingface:reddit', 'huggingface:reddit_tifu', 'huggingface:refresd', 'huggingface:reuters21578', 'huggingface:riddle_sense', 'huggingface:ro_sent', 'huggingface:ro_sts', 'huggingface:ro_sts_parallel', 'huggingface:roman_urdu', 'huggingface:roman_urdu_hate_speech', 'huggingface:ronec', 'huggingface:ropes', 'huggingface:rotten_tomatoes', 'huggingface:russian_super_glue', 'huggingface:rvl_cdip', 'huggingface:s2orc', 'huggingface:samsum', 'huggingface:sanskrit_classic', 'huggingface:saudinewsnet', 'huggingface:sberquad', 'huggingface:sbu_captions', 'huggingface:scan', 'huggingface:scb_mt_enth_2020', 'huggingface:scene_parse_150', 'huggingface:schema_guided_dstc8', 'huggingface:scicite', 'huggingface:scielo', 'huggingface:scientific_papers', 'huggingface:scifact', 'huggingface:sciq', 'huggingface:scitail', 'huggingface:scitldr', 'huggingface:search_qa', 'huggingface:sede', 'huggingface:selqa', 'huggingface:sem_eval_2010_task_8', 'huggingface:sem_eval_2014_task_1', 'huggingface:sem_eval_2018_task_1', 'huggingface:sem_eval_2020_task_11', 'huggingface:sent_comp', 'huggingface:senti_lex', 'huggingface:senti_ws', 'huggingface:sentiment140', 'huggingface:sepedi_ner', 'huggingface:sesotho_ner_corpus', 'huggingface:setimes', 'huggingface:setswana_ner_corpus', 'huggingface:sharc', 'huggingface:sharc_modified', 'huggingface:sick', 'huggingface:silicone', 'huggingface:simple_questions_v2', 'huggingface:siswati_ner_corpus', 'huggingface:smartdata', 'huggingface:sms_spam', 'huggingface:snips_built_in_intents', 'huggingface:snli', 'huggingface:snow_simplified_japanese_corpus', 'huggingface:so_stacksample', 'huggingface:social_bias_frames', 'huggingface:social_i_qa', 'huggingface:sofc_materials_articles', ...]
We will be using the imdb reviews dataset as our dataset for the session today. This is a text classification dataset where each label can be 0 or 1, indicating a positive or negative review.
# Split the training set into 60% and 40% to end up with 15,000 examples
# for training, 10,000 examples for validation and 25,000 examples for testing.
train_data, validation_data, test_data = tfds.load(
name="imdb_reviews",
split=('train[:60%]', 'train[60%:]', 'test'),
as_supervised=True)
Downloading and preparing dataset 80.23 MiB (download: 80.23 MiB, generated: Unknown size, total: 80.23 MiB) to /root/tensorflow_datasets/imdb_reviews/plain_text/1.0.0...
Dl Completed...: 0 url [00:00, ? url/s]
Dl Size...: 0 MiB [00:00, ? MiB/s]
Generating splits...: 0%| | 0/3 [00:00<?, ? splits/s]
Generating train examples...: 0%| | 0/25000 [00:00<?, ? examples/s]
Shuffling /root/tensorflow_datasets/imdb_reviews/plain_text/1.0.0.incompleteEJYEOD/imdb_reviews-train.tfrecord…
Generating test examples...: 0%| | 0/25000 [00:00<?, ? examples/s]
Shuffling /root/tensorflow_datasets/imdb_reviews/plain_text/1.0.0.incompleteEJYEOD/imdb_reviews-test.tfrecord*…
Generating unsupervised examples...: 0%| | 0/50000 [00:00<?, ? examples/s]
Shuffling /root/tensorflow_datasets/imdb_reviews/plain_text/1.0.0.incompleteEJYEOD/imdb_reviews-unsupervised.t…
Dataset imdb_reviews downloaded and prepared to /root/tensorflow_datasets/imdb_reviews/plain_text/1.0.0. Subsequent calls will reuse this data.
train_data = train_data.shuffle(10)
text_batch, label_batch = next(iter(train_data.batch(5)))
for i in range(5):
print("Review: ", text_batch.numpy()[i])
print("Label:", label_batch.numpy()[i])
Review: b'As others have mentioned, all the women that go nude in this film are mostly absolutely gorgeous. The plot very ably shows the hypocrisy of the female libido. When men are around they want to be pursued, but when no "men" are around, they become the pursuers of a 14 year old boy. And the boy becomes a man really fast (we should all be so lucky at this age!). He then gets up the courage to pursue his true love.' Label: 1 Review: b'This is the kind of film for a snowy Sunday afternoon when the rest of the world can go ahead with its own business as you descend into a big arm-chair and mellow for a couple of hours. Wonderful performances from Cher and Nicolas Cage (as always) gently row the plot along. There are no rapids to cross, no dangerous waters, just a warm and witty paddle through New York life at its best. A family film in every sense and one that deserves the praise it received.' Label: 1 Review: b'Okay, you have:<br /><br />Penelope Keith as Miss Herringbone-Tweed, B.B.E. (Backbone of England.) She\'s killed off in the first scene - that\'s right, folks; this show has no backbone!<br /><br />Peter O\'Toole as Ol\' Colonel Cricket from The First War and now the emblazered Lord of the Manor.<br /><br />Joanna Lumley as the ensweatered Lady of the Manor, 20 years younger than the colonel and 20 years past her own prime but still glamourous (Brit spelling, not mine) enough to have a toy-boy on the side. It\'s alright, they have Col. Cricket\'s full knowledge and consent (they guy even comes \'round for Christmas!) Still, she\'s considerate of the colonel enough to have said toy-boy her own age (what a gal!)<br /><br />David McCallum as said toy-boy, equally as pointlessly glamourous as his squeeze. Pilcher couldn\'t come up with any cover for him within the story, so she gave him a hush-hush job at the Circus.<br /><br />and finally:<br /><br />Susan Hampshire as Miss Polonia Teacups, Venerable Headmistress of the Venerable Girls\' Boarding-School, serving tea in her office with a dash of deep, poignant advice for life in the outside world just before graduation. Her best bit of advice: "I\'ve only been to Nancherrow (the local Stately Home of England) once. I thought it was very beautiful but, somehow, not part of the real world." Well, we can\'t say they didn\'t warn us.<br /><br />Ah, Susan - time was, your character would have been running the whole show. They don\'t write \'em like that any more. Our loss, not yours.<br /><br />So - with a cast and setting like this, you have the re-makings of "Brideshead Revisited," right?<br /><br />Wrong! They took these 1-dimensional supporting roles because they paid so well. After all, acting is one of the oldest temp-jobs there is (YOU name another!)<br /><br />First warning sign: lots and lots of backlighting. They get around it by shooting outdoors - "hey, it\'s just the sunlight!"<br /><br />Second warning sign: Leading Lady cries a lot. When not crying, her eyes are moist. That\'s the law of romance novels: Leading Lady is "dewy-eyed."<br /><br />Henceforth, Leading Lady shall be known as L.L.<br /><br />Third warning sign: L.L. actually has stars in her eyes when she\'s in love. Still, I\'ll give Emily Mortimer an award just for having to act with that spotlight in her eyes (I wonder . did they use contacts?)<br /><br />And lastly, fourth warning sign: no on-screen female character is "Mrs." She\'s either "Miss" or "Lady."<br /><br />When all was said and done, I still couldn\'t tell you who was pursuing whom and why. I couldn\'t even tell you what was said and done.<br /><br />To sum up: they all live through World War II without anything happening to them at all.<br /><br />OK, at the end, L.L. finds she\'s lost her parents to the Japanese prison camps and baby sis comes home catatonic. Meanwhile (there\'s always a "meanwhile,") some young guy L.L. had a crush on (when, I don\'t know) comes home from some wartime tough spot and is found living on the street by Lady of the Manor (must be some street if SHE\'s going to find him there.) Both war casualties are whisked away to recover at Nancherrow (SOMEBODY has to be "whisked away" SOMEWHERE in these romance stories!)<br /><br />Great drama.' Label: 0 Review: b'Cute film about three lively sisters from Switzerland (often seen running about in matching outfits) who want to get their parents back together (seems mom is still carrying the torch for dad) - so they sail off to New York to stop the dad from marrying a blonde gold-digger he calls "Precious". Dad hasn\'t seen his daughters in ten years, they (oddly enough) don\'t seem to mind and think he\'s wonderful, and meanwhile Precious seems to lead a life mainly run by her overbearing mother (Alice Brady), a woman who just wants to see to it her daughter marries a rich man. The sisters get the idea of pushing Precious into the path of a drunken Hungarian count, tricking the two gold-digging women into thinking he is one of the richest men in Europe. But a case of mistaken identity makes the girls think the count is good-looking Ray Milland, who goes along with the scheme \'cause he has a crush on sister Kay.<br /><br />This film is enjoyable, light fare. Barbara Read as Kay comes across as sweet and pretty, Ray Milland looks oh so young and handsome here (though, unfortunately, is given little to do), Alice Brady is quite good as the scheming mother - but it is Deanna Durbin, a real charmer and cute as a button playing youngest sister Penny, who pretty much steals the show. With absolutely beautiful vocals, she sings several songs throughout the film, though I actually would have liked to have seen them feature her even more in this. The plot in this film is a bit silly, but nevertheless, I found the film to be entertaining and fun.' Label: 1 Review: b'Put the blame on executive producer Wes Craven and financiers the Weinsteins for this big-budget debacle: a thrash-metal updating of "Dracula", with a condescending verbal jab at Bram Stoker (who probably wouldn\'t want his name on this thing anyway) and nothing much for the rest of us except slasher-styled jolts and gore. Christopher Plummer looks winded as Van Helsing in the modern-day--not just a descendant of Van Helsing but the real thing; he keeps himself going with leeches obtained from Count Dracula\'s corpse, which is exhumed from its coffin after being stolen from Van Helsing\'s vault and flown to New Orleans. This is just what New Orleans needs in the 21st Century! The film, well-produced but without a single original idea (except for multi-racial victims), is both repulsive and lazy, and after about an hour starts repeating itself. * from ****' Label: 0
1.2 Tokenization¶
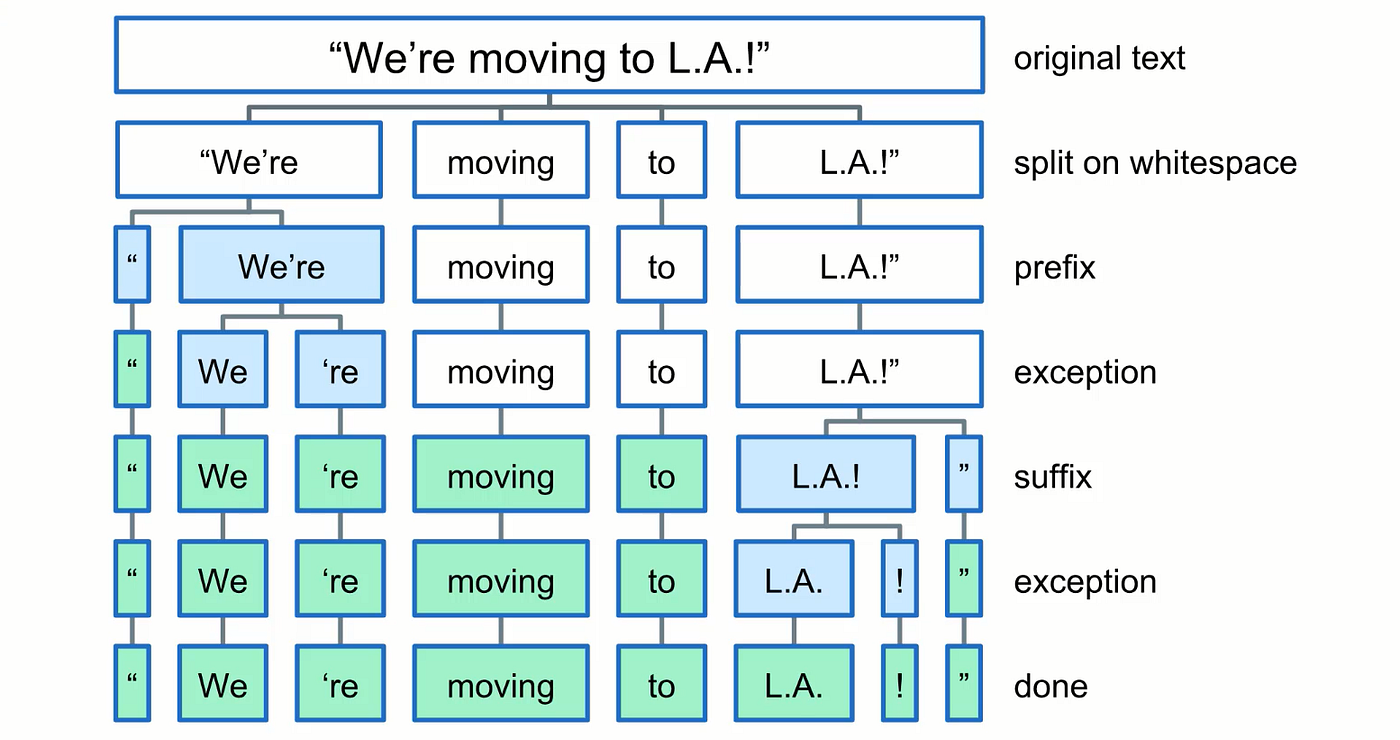
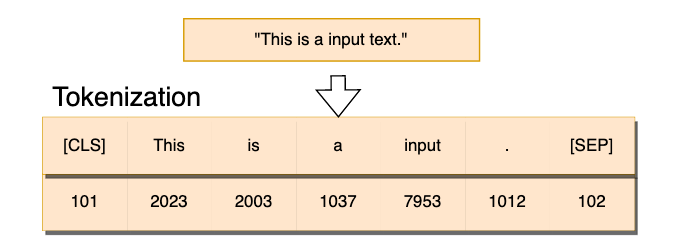
Tokenization is when we split our text into chunks and assign each of them a unique numerical ID.
word = "silent"
another_word = "listen"
[ord(char) for char in word]
[115, 105, 108, 101, 110, 116]
[ord(char) for char in another_word]
[108, 105, 115, 116, 101, 110]
raw_data = text_batch.numpy()
raw_data
array([b'As others have mentioned, all the women that go nude in this film are mostly absolutely gorgeous. The plot very ably shows the hypocrisy of the female libido. When men are around they want to be pursued, but when no "men" are around, they become the pursuers of a 14 year old boy. And the boy becomes a man really fast (we should all be so lucky at this age!). He then gets up the courage to pursue his true love.',
b'This is the kind of film for a snowy Sunday afternoon when the rest of the world can go ahead with its own business as you descend into a big arm-chair and mellow for a couple of hours. Wonderful performances from Cher and Nicolas Cage (as always) gently row the plot along. There are no rapids to cross, no dangerous waters, just a warm and witty paddle through New York life at its best. A family film in every sense and one that deserves the praise it received.',
b'Okay, you have:<br /><br />Penelope Keith as Miss Herringbone-Tweed, B.B.E. (Backbone of England.) She\'s killed off in the first scene - that\'s right, folks; this show has no backbone!<br /><br />Peter O\'Toole as Ol\' Colonel Cricket from The First War and now the emblazered Lord of the Manor.<br /><br />Joanna Lumley as the ensweatered Lady of the Manor, 20 years younger than the colonel and 20 years past her own prime but still glamourous (Brit spelling, not mine) enough to have a toy-boy on the side. It\'s alright, they have Col. Cricket\'s full knowledge and consent (they guy even comes \'round for Christmas!) Still, she\'s considerate of the colonel enough to have said toy-boy her own age (what a gal!)<br /><br />David McCallum as said toy-boy, equally as pointlessly glamourous as his squeeze. Pilcher couldn\'t come up with any cover for him within the story, so she gave him a hush-hush job at the Circus.<br /><br />and finally:<br /><br />Susan Hampshire as Miss Polonia Teacups, Venerable Headmistress of the Venerable Girls\' Boarding-School, serving tea in her office with a dash of deep, poignant advice for life in the outside world just before graduation. Her best bit of advice: "I\'ve only been to Nancherrow (the local Stately Home of England) once. I thought it was very beautiful but, somehow, not part of the real world." Well, we can\'t say they didn\'t warn us.<br /><br />Ah, Susan - time was, your character would have been running the whole show. They don\'t write \'em like that any more. Our loss, not yours.<br /><br />So - with a cast and setting like this, you have the re-makings of "Brideshead Revisited," right?<br /><br />Wrong! They took these 1-dimensional supporting roles because they paid so well. After all, acting is one of the oldest temp-jobs there is (YOU name another!)<br /><br />First warning sign: lots and lots of backlighting. They get around it by shooting outdoors - "hey, it\'s just the sunlight!"<br /><br />Second warning sign: Leading Lady cries a lot. When not crying, her eyes are moist. That\'s the law of romance novels: Leading Lady is "dewy-eyed."<br /><br />Henceforth, Leading Lady shall be known as L.L.<br /><br />Third warning sign: L.L. actually has stars in her eyes when she\'s in love. Still, I\'ll give Emily Mortimer an award just for having to act with that spotlight in her eyes (I wonder . did they use contacts?)<br /><br />And lastly, fourth warning sign: no on-screen female character is "Mrs." She\'s either "Miss" or "Lady."<br /><br />When all was said and done, I still couldn\'t tell you who was pursuing whom and why. I couldn\'t even tell you what was said and done.<br /><br />To sum up: they all live through World War II without anything happening to them at all.<br /><br />OK, at the end, L.L. finds she\'s lost her parents to the Japanese prison camps and baby sis comes home catatonic. Meanwhile (there\'s always a "meanwhile,") some young guy L.L. had a crush on (when, I don\'t know) comes home from some wartime tough spot and is found living on the street by Lady of the Manor (must be some street if SHE\'s going to find him there.) Both war casualties are whisked away to recover at Nancherrow (SOMEBODY has to be "whisked away" SOMEWHERE in these romance stories!)<br /><br />Great drama.',
b'Cute film about three lively sisters from Switzerland (often seen running about in matching outfits) who want to get their parents back together (seems mom is still carrying the torch for dad) - so they sail off to New York to stop the dad from marrying a blonde gold-digger he calls "Precious". Dad hasn\'t seen his daughters in ten years, they (oddly enough) don\'t seem to mind and think he\'s wonderful, and meanwhile Precious seems to lead a life mainly run by her overbearing mother (Alice Brady), a woman who just wants to see to it her daughter marries a rich man. The sisters get the idea of pushing Precious into the path of a drunken Hungarian count, tricking the two gold-digging women into thinking he is one of the richest men in Europe. But a case of mistaken identity makes the girls think the count is good-looking Ray Milland, who goes along with the scheme \'cause he has a crush on sister Kay.<br /><br />This film is enjoyable, light fare. Barbara Read as Kay comes across as sweet and pretty, Ray Milland looks oh so young and handsome here (though, unfortunately, is given little to do), Alice Brady is quite good as the scheming mother - but it is Deanna Durbin, a real charmer and cute as a button playing youngest sister Penny, who pretty much steals the show. With absolutely beautiful vocals, she sings several songs throughout the film, though I actually would have liked to have seen them feature her even more in this. The plot in this film is a bit silly, but nevertheless, I found the film to be entertaining and fun.',
b'Put the blame on executive producer Wes Craven and financiers the Weinsteins for this big-budget debacle: a thrash-metal updating of "Dracula", with a condescending verbal jab at Bram Stoker (who probably wouldn\'t want his name on this thing anyway) and nothing much for the rest of us except slasher-styled jolts and gore. Christopher Plummer looks winded as Van Helsing in the modern-day--not just a descendant of Van Helsing but the real thing; he keeps himself going with leeches obtained from Count Dracula\'s corpse, which is exhumed from its coffin after being stolen from Van Helsing\'s vault and flown to New Orleans. This is just what New Orleans needs in the 21st Century! The film, well-produced but without a single original idea (except for multi-racial victims), is both repulsive and lazy, and after about an hour starts repeating itself. * from ****'],
dtype=object)
plain_text = [i.decode("utf-8") for i in raw_data]
print(plain_text[0])
As others have mentioned, all the women that go nude in this film are mostly absolutely gorgeous. The plot very ably shows the hypocrisy of the female libido. When men are around they want to be pursued, but when no "men" are around, they become the pursuers of a 14 year old boy. And the boy becomes a man really fast (we should all be so lucky at this age!). He then gets up the courage to pursue his true love.
word_tokenized = []
for i in range(len(plain_text)):
word_tokenized.append(tf.keras.preprocessing.text.text_to_word_sequence(plain_text[i]))
word_tokenized[0]
['as', 'others', 'have', 'mentioned', 'all', 'the', 'women', 'that', 'go', 'nude', 'in', 'this', 'film', 'are', 'mostly', 'absolutely', 'gorgeous', 'the', 'plot', 'very', 'ably', 'shows', 'the', 'hypocrisy', 'of', 'the', 'female', 'libido', 'when', 'men', 'are', 'around', 'they', 'want', 'to', 'be', 'pursued', 'but', 'when', 'no', 'men', 'are', 'around', 'they', 'become', 'the', 'pursuers', 'of', 'a', '14', 'year', 'old', 'boy', 'and', 'the', 'boy', 'becomes', 'a', 'man', 'really', 'fast', 'we', 'should', 'all', 'be', 'so', 'lucky', 'at', 'this', 'age', 'he', 'then', 'gets', 'up', 'the', 'courage', 'to', 'pursue', 'his', 'true', 'love']
max_num_words = 10000
tokenizer = tf.keras.preprocessing.text.Tokenizer(num_words=max_num_words)
tokenizer.fit_on_texts(word_tokenized)
tokens = tokenizer.texts_to_sequences(word_tokenized)
print(tokens[0])
[8, 174, 14, 175, 25, 1, 90, 40, 91, 176, 9, 11, 15, 26, 177, 92, 178, 1, 49, 93, 179, 180, 1, 181, 5, 1, 94, 182, 20, 50, 26, 51, 10, 52, 6, 27, 183, 18, 20, 33, 50, 26, 51, 10, 184, 1, 185, 5, 3, 186, 187, 188, 34, 4, 1, 34, 189, 3, 95, 190, 191, 96, 192, 25, 27, 28, 193, 21, 11, 97, 35, 194, 195, 53, 1, 196, 6, 197, 41, 198, 98]
1.3 Vectorization¶
# Convert the dataset from a gen into dataset format
text_batch, label_batch = next(iter(train_data.batch(128)))
text_dataset = tf.data.Dataset.from_tensor_slices(text_batch)
text_dataset
<_TensorSliceDataset element_spec=TensorSpec(shape=(), dtype=tf.string, name=None)>
vectorize_layer = tf.keras.layers.TextVectorization(
max_tokens=max_num_words,
output_mode='int',
output_sequence_length=10)
vectorize_layer.adapt(text_dataset.batch(64))
vectorize_layer.get_vocabulary()
['', '[UNK]', 'the', 'of', 'and', 'a', 'to', 'is', 'in', 'this', 'i', 'it', 'that', 'br', 'as', 'with', 'for', 'was', 'film', 'you', 'movie', 'but', 'are', 'one', 'have', 'be', 'on', 'his', 'not', 'all', 'they', 'just', 'an', 'by', 'from', 'at', 'so', 'her', 'who', 'has', 'its', 'he', 'if', 'about', 'what', 'some', 'or', 'like', 'no', 'my', 'when', 'there', 'their', 'out', 'she', 'which', 'will', 'more', 'good', 'see', 'first', 'me', 'would', 'most', 'them', 'up', 'had', 'get', 'well', 'too', 'other', 'movies', 'do', 'even', 'story', 'people', 'only', 'into', 'dont', 'were', 'very', 'can', 'really', 'also', 'way', 'then', 'seen', 'any', 'great', 'been', 'we', 'many', 'than', 'how', 'ever', 'think', 'these', 'should', 'time', 'much', 'make', 'films', 'actors', 'could', 'best', 'while', 'plot', 'did', 'after', 'him', 'say', 'because', 'three', 'such', 'still', 'scenes', 'made', 'end', 'being', 'world', 'thing', 'know', 'bad', 'why', 'want', 'two', 'through', 'real', 'pretty', 'go', 'character', 'big', 'us', 'scene', 'own', 'nothing', 'never', 'lot', 'im', 'every', 'your', 'yet', 'take', 'show', 'off', 'life', 'enough', 'doesnt', 'does', 'cast', 'acting', 'those', 'quite', 'little', 'funny', 'few', 'whole', 'where', 'over', 'makes', 'ive', 'back', '\x96', 'watch', 'saw', 'right', 'performance', 'our', 'man', 'king', 'hollywood', 'here', 'find', 'better', 'another', 'years', 'same', 'new', 'love', 'down', 'director', 'come', 'before', 'around', 'though', 'old', 'now', 'give', 'gets', 'characters', 'without', 'thats', 'something', 'script', 'part', 'might', 'isnt', 'going', 'girl', 'family', 'tv', 'throughout', 'last', 'home', 'having', 'feel', 'each', 'didnt', 'both', 'always', 'actually', 'actor', 'watching', 'theres', 'simply', 'shes', 'role', 'place', 'name', 'minutes', 'high', 'fact', 'done', 'comedy', 'between', 'again', 'youre', 'work', 'trying', 'true', 'tell', 'since', 'seems', 'may', 'looks', 'enjoy', 'young', 'thought', 'things', 'sense', 'second', 'read', 'point', 'performances', 'mean', 'lion', 'lets', 'let', 'head', 'guy', 'goes', 'course', 'bit', 'believe', 'away', 'action', 'absolutely', 'worst', 'turn', 'seeing', 'rather', 'production', 'once', 'must', 'lucy', 'least', 'kids', 'instead', 'however', 'house', 'fun', 'far', 'especially', 'day', 'yes', 'unfortunately', 'reason', 'quantum', 'look', 'lives', 'liked', 'idea', 'himself', 'hes', 'evil', 'comes', 'cant', 'beautiful', 'am', 'age', 'wife', 'truly', 'town', 'theyre', 'sure', 'short', 'series', 'seem', 'said', 'rest', 'recommend', 'problem', 'oh', 'nice', 'need', 'music', 'mind', 'main', 'lots', 'line', 'kind', 'job', 'humor', 'horror', 'given', 'fans', 'executive', 'either', 'during', 'completely', 'classic', 'called', 'bach', 'american', 'wont', 'wonderful', 'wonder', 'used', 'timon', 'takes', 'start', 'seriously', 'seemed', 'room', 'remember', 'pumbaa', 'perhaps', 'ones', 'often', 'night', 'money', 'making', 'less', 'interesting', 'full', 'eyes', 'excellent', 'etc', 'episodes', 'ending', 'dvd', 'doing', 'couldnt', 'casting', 'cannot', 'camera', 'behind', 'based', 'awful', 'audience', 'anything', 'anyone', 'along', 'wants', 'understand', 'top', 'took', 'times', 'style', 'studio', 'streisand', 'stars', 'shows', 'shots', 'sets', 'set', 'screen', 'says', 'rachel', 'poor', 'particularly', 'others', 'mr', 'late', 'girls', 'gave', 'fuqua', 'foxx', 'found', 'fine', 'finally', 'felt', 'fan', 'except', 'everything', 'everyone', 'entire', 'else', 'easy', 'early', 'close', 'city', 'christmas', 'certainly', 'canadian', 'book', 'beginning', 'avoid', 'appropriate', 'anyway', 'although', 'almost', 'against', 'act', 'york', 'worth', 'words', 'woman', 'warning', 'version', 'use', 'upon', 'until', 'twist', 'turned', 'try', 'together', 'thinking', 'tale', 'surprised', 'stupid', 'strong', 'star', 'sort', 'someone', 'slugs', 'similar', 'side', 'scrooge', 'scott', 'school', 'probably', 'play', 'piece', 'past', 'named', 'mother', 'michael', 'men', 'memorable', 'meet', 'meanwhile', 'married', 'looking', 'local', 'lady', 'known', 'killed', 'jokes', 'john', 'jean', 'human', 'hilarious', 'festival', 'female', 'famous', 'expect', 'example', 'episode', 'entertaining', 'deathstalker', 'dead', 'coming', 'buy', 'boy', 'black', 'basic', 'barbra', 'bait', 'arthur', 'art', 'arent', 'appeared', 'able', 'youve', 'youll', 'written', 'wish', 'watched', 'wasnt', 'war', 'waiting', 'video', 'usually', 'under', 'type', 'therefore', 'terrible', 'team', 'sword', 'supporting', 'stay', 'starts', 'spirit', 'space', 'sometimes', 'small', 'sister', 'shorts', 'serious', 'sad', 'running', 'roles', 'realize', 'reality', 'portrayal', 'plays', 'played', 'peter', 'perfect', 'paul', 'parents', 'overall', 'original', 'note', 'nor', 'negative', 'nearly', 'missed', 'miss', 'maybe', 'mall', 'lord', 'long', 'leave', 'leading', 'ill', 'ideas', 'id', 'hit', 'history', 'hero', 'hand', 'guys', 'got', 'gives', 'genre', 'filmbr', 'feeling', 'favorite', 'fast', 'familiar', 'eye', 'enjoyed', 'emotional', 'easily', 'disappointed', 'decent', 'days', 'couple', 'comment', 'comic', 'cinema', 'career', 'care', 'car', 'bunch', 'bring', 'brilliant', 'bright', 'books', 'band', 'animation', '3', '12', '\x85', 'yourself', 'younger', 'year', 'word', 'wild', 'whom', 'werent', 'weird', 'warrior', 'truth', 'tries', 'thrown', 'theory', 'themselves', 'superb', 'street', 'strange', 'stories', 'stooges', 'stage', 'songs', 'song', 'somewhat', 'slow', 'skull', 'silly', 'sign', 'setting', 'sadly', 'run', 'rich', 'review', 'return', 'remarkable', 'red', 'question', 'quality', 'previous', 'presidents', 'premise', 'possibly', 'physics', 'particular', 'particles', 'oscar', 'ok', 'number', 'nancy', 'naked', 'muni', 'mrs', 'moments', 'meant', 'matter', 'material', 'male', 'lynch', 'loved', 'lost', 'lines', 'level', 'leaves', 'lamm', 'kelly', 'keller', 'keep', 'james', 'itself', 'itbr', 'immediately', 'imagination', 'hours', 'highly', 'help', 'hell', 'havent', 'harlow', 'happens', 'happen', 'guess', 'greatest', 'gone', 'fuquas', 'friend', 'fresh', 'floor', 'fire', 'fight', 'father', 'extremely', 'escape', 'enjoyable', 'effects', 'drama', 'directors', 'directed', 'died', 'die', 'described', 'decided', 'decide', 'david', 'daughter', 'dark', 'cute', 'crap', 'count', 'control', 'comments', 'change', 'case', 'carry', 'came', 'cal', 'bourne', 'bored', 'become', 'basically', 'available', 'attention', 'atmosphere', 'apparently', 'apart', 'annoying', 'andre', 'amusing', 'already', 'ago', 'add', 'actress', 'ability', '2', 'wrote', 'wrong', 'writers', 'writer', 'worse', 'women', 'within', 'winner', 'williams', 'whos', 'went', 'weekly', 'ways', 'waste', 'unlike', 'understanding', 'tournament', 'tough', 'touching', 'touch', 'totally', 'tim', 'themes', 'teachers', 'taken', 'superhero', 'straight', 'store', 'stop', 'spoilers', 'sound', 'sorry', 'solvang', 'solid', 'smart', 'skilled', 'sit', 'sidney', 'sexual', 'sex', 'sensitive', 'screaming', 'schools', 'saying', 'saved', 'save', 'satisfying', 'romance', 'roger', 'robert', 'richard', 'rent', 'reminds', 'pushing', 'producers', 'problems', 'princess', 'predictable', 'precious', 'powerful', 'positive', 'popular', 'playing', 'phantom', 'peptides', 'pathetic', 'parts', 'originally', 'order', 'opinion', 'opening', 'office', 'nowhere', 'normal', 'none', 'no2', 'no1', 'nightmare', 'near', 'nature', 'mystery', 'myself', 'musical', 'moving', 'missouri', 'middle', 'message', 'merely', 'means', 'matt', 'magic', 'luise', 'loss', 'live', 'list', 'light', 'left', 'leads', 'law', 'laugh', 'lana', 'lame', 'ladies', 'lacks', 'kept', 'interested', 'information', 'incredibly', 'including', 'husband', 'hope', 'holiday', 'hold', 'heard', 'hasnt', 'happy', 'half', 'group', 'gorgeous', 'god', 'getting', 'george', 'general', 'game', 'friends', 'frank', 'fourth', 'forward', 'forget', 'force', 'folks', 'finish', 'final', 'figure', 'fights', 'feature', 'fart', 'fantastic', 'false', 'falls', 'fall', 'face', 'expression', 'explanation', 'expected', 'exactly', 'exact', 'ends', 'emotions', 'due', 'dixon', 'disturbing', 'disney', 'different', 'dialogue', 'development', 'detail', 'definitely', 'cut', 'critics', 'creative', 'copy', 'convincing', 'convey', 'continue', 'considering', 'closer', 'clearly', 'clarkson', 'christopher', 'children', 'cheap', 'candy', 'calls', 'brothers', 'bromwell', 'brings', 'box', 'bottom', 'boring', 'body', 'blood', 'beyond', 'background', 'attempt', 'artsy', 'approach', 'appear', 'anybody', 'amazing', 'al', 'air', 'advice', 'actresses', 'accept', '20', '1', 'zombi', 'wouldnt', 'works', 'whose', 'whenever', 'whats', 'whatever', 'welcome', 'weak', 'wasted', 'wanted', 'wait', 'voice', 'village', 'viewers', 'viewer', 'view', 'various', 'variety', 'van', 'value', 'usbr', 'unseen', 'universal', 'uniquely', 'unique', 'underrated', 'unbelievable', 'typically', 'typical', 'transfer', 'tragic', 'toyboy', 'total', 'tone', 'told', 'todesking', 'titanic', 'tired', 'threatening', 'thin', 'thank', 'ten', 'tells', 'teenagers', 'target', 'talking', 'taking', 'sympathy', 'susan', 'surrounded', 'surprises', 'supposed', 'suppose', 'summer', 'suffering', 'suffer', 'subtle', 'subatomic', 'stuff', 'study', 'student', 'stuck', 'stone', 'stick', 'steven', 'state', 'started', 'standard', 'spectacular', 'special', 'speaking', 'spanish', 'soundtrack', 'son', 'somehow', 'solar', 'society', 'social', 'slave', 'sky', 'sixties', 'sisters', 'sings', 'single', 'sing', 'simple', 'shown', 'shot', 'shame', 'several', 'sequel', 'sell', 'segal', 'secret', ...]
demo_model = tf.keras.models.Sequential([vectorize_layer])
demo_model.predict([["This is a sentence."],
["This is another sentence."]])
1/1 [==============================] - 2s 2s/step
array([[ 9, 7, 5, 1, 0, 0, 0, 0, 0, 0],
[ 9, 7, 174, 1, 0, 0, 0, 0, 0, 0]])
1.4 Word Embeddings¶
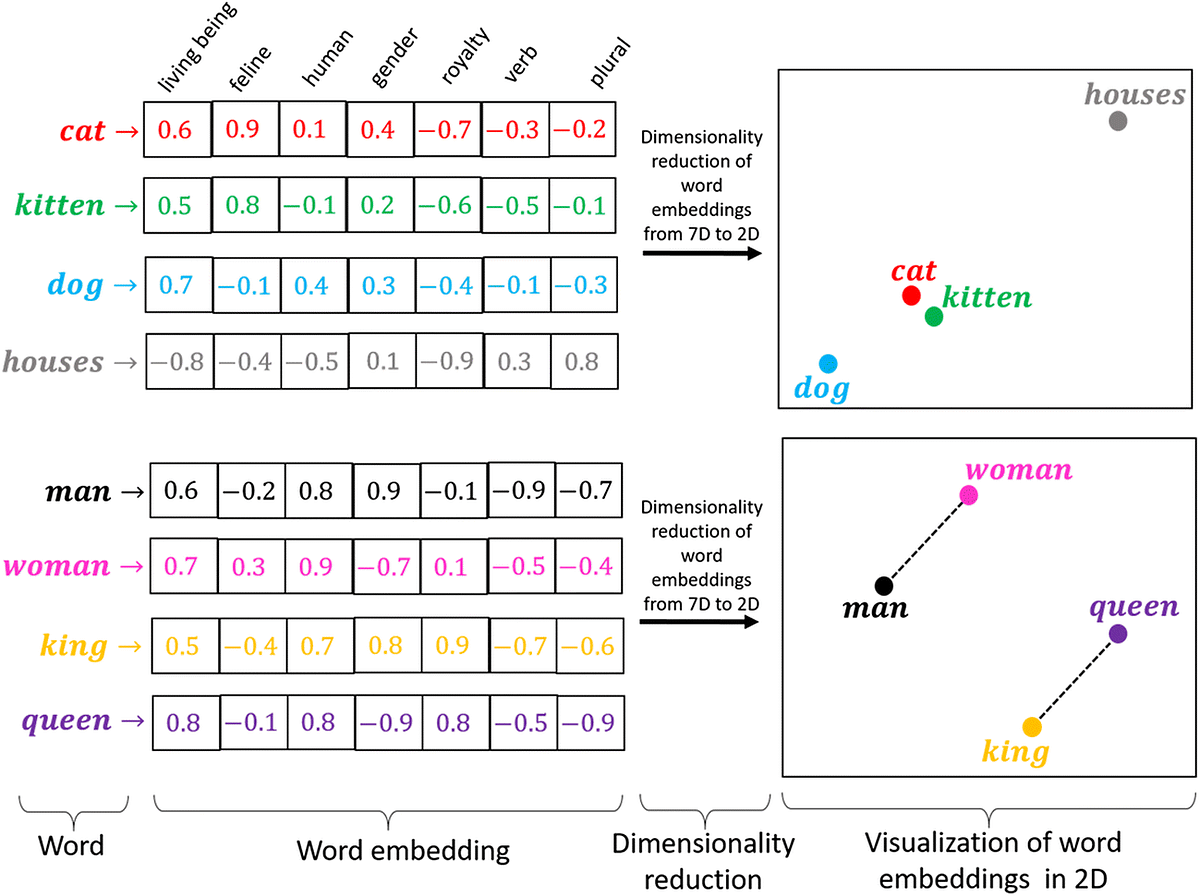
Rather than simply converting the words into integers each word is converted into a vector of floats that can better represent the meanings and relations between different words.
vector_size = 5
embedding_layer = tf.keras.layers.Embedding(max_num_words, vector_size)
encodings = demo_model.predict([["This is a sentence."]])
print(encodings)
embeddings = embedding_layer(tf.constant(encodings))
print(embeddings)
print(encodings.shape, embeddings.shape)
1/1 [==============================] - 0s 29ms/step [[9 7 5 1 0 0 0 0 0 0]] tf.Tensor( [[[-0.00929177 -0.02961112 0.01572095 -0.00546347 -0.04501405] [ 0.04436645 0.02971524 -0.02868166 -0.02332792 0.03999862] [-0.04126833 0.03574758 -0.02727452 -0.03438221 0.01604876] [-0.02054843 0.036926 -0.04109913 -0.03033973 0.02770685] [-0.03339513 0.04378723 -0.02956108 -0.02224633 -0.00406911] [-0.03339513 0.04378723 -0.02956108 -0.02224633 -0.00406911] [-0.03339513 0.04378723 -0.02956108 -0.02224633 -0.00406911] [-0.03339513 0.04378723 -0.02956108 -0.02224633 -0.00406911] [-0.03339513 0.04378723 -0.02956108 -0.02224633 -0.00406911] [-0.03339513 0.04378723 -0.02956108 -0.02224633 -0.00406911]]], shape=(1, 10, 5), dtype=float32) (1, 10) (1, 10, 5)
We can explore a dataset of complex imbeddings at this site embed_visu .
We can also use pre-trained models from tensorflow-hub to create embeddings for our data.
2. Training a Model¶
2.1 Model with Tokenization¶
For the first model, we only use tokenization to construct the model.
max_num_words = 32 * 10**3
vectorize_layer = tf.keras.layers.TextVectorization(
max_tokens=max_num_words,
output_mode='int',
output_sequence_length=10)
vectorize_layer.adapt(text_dataset)
model = tf.keras.models.Sequential([])
model.add(vectorize_layer)
model.add(tf.keras.layers.Dense(256, activation='relu'))
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dense(64, activation='relu'))
model.add(tf.keras.layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
history = model.fit(train_data.shuffle(10000).batch(512),
epochs=10,
validation_data=validation_data.batch(512),
verbose=1)
Epoch 1/10
/usr/local/lib/python3.10/dist-packages/keras/src/backend.py:5818: UserWarning: "`binary_crossentropy` received `from_logits=True`, but the `output` argument was produced by a Sigmoid activation and thus does not represent logits. Was this intended? output, from_logits = _get_logits(
30/30 [==============================] - 6s 79ms/step - loss: 21.2472 - accuracy: 0.5035 - val_loss: 5.6720 - val_accuracy: 0.5039 Epoch 2/10 30/30 [==============================] - 2s 49ms/step - loss: 3.9529 - accuracy: 0.4993 - val_loss: 3.1013 - val_accuracy: 0.5024 Epoch 3/10 30/30 [==============================] - 3s 89ms/step - loss: 2.5204 - accuracy: 0.5208 - val_loss: 2.6518 - val_accuracy: 0.5077 Epoch 4/10 30/30 [==============================] - 2s 50ms/step - loss: 2.1447 - accuracy: 0.5248 - val_loss: 2.2500 - val_accuracy: 0.5135 Epoch 5/10 30/30 [==============================] - 2s 51ms/step - loss: 1.9726 - accuracy: 0.5207 - val_loss: 2.1544 - val_accuracy: 0.5062 Epoch 6/10 30/30 [==============================] - 2s 51ms/step - loss: 1.6089 - accuracy: 0.5340 - val_loss: 2.2512 - val_accuracy: 0.5040 Epoch 7/10 30/30 [==============================] - 2s 51ms/step - loss: 1.7370 - accuracy: 0.5302 - val_loss: 2.1943 - val_accuracy: 0.5019 Epoch 8/10 30/30 [==============================] - 2s 62ms/step - loss: 1.6039 - accuracy: 0.5445 - val_loss: 2.0347 - val_accuracy: 0.5107 Epoch 9/10 30/30 [==============================] - 2s 51ms/step - loss: 1.4045 - accuracy: 0.5477 - val_loss: 1.9095 - val_accuracy: 0.5039 Epoch 10/10 30/30 [==============================] - 2s 49ms/step - loss: 1.5053 - accuracy: 0.5453 - val_loss: 2.0738 - val_accuracy: 0.5107
from matplotlib import pyplot as plt
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'val'], loc='upper left')
plt.show()

plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'val'], loc='upper right')
plt.show()

2.2 Model with Tokenization and Embeddings¶
Now we add an embedding layer to our model.
max_num_words = 32 * 10**3
vectorize_layer = tf.keras.layers.TextVectorization(
max_tokens=max_num_words,
output_mode='int',
output_sequence_length=10)
vector_size = 16
embedding_layer = tf.keras.layers.Embedding(max_num_words, vector_size)
vectorize_layer.adapt(text_dataset)
model = tf.keras.models.Sequential([])
model.add(vectorize_layer)
model.add(embedding_layer)
model.add(tf.keras.layers.GlobalAveragePooling1D(),)
model.add(tf.keras.layers.Dense(256, activation='relu'))
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dense(64, activation='relu'))
model.add(tf.keras.layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
history = model.fit(train_data.shuffle(10000).batch(512),
epochs=10,
validation_data=validation_data.batch(512),
verbose=1)
Epoch 1/10 30/30 [==============================] - 10s 224ms/step - loss: 0.6902 - accuracy: 0.5380 - val_loss: 0.6817 - val_accuracy: 0.5790 Epoch 2/10 30/30 [==============================] - 6s 203ms/step - loss: 0.6398 - accuracy: 0.6440 - val_loss: 0.6383 - val_accuracy: 0.6364 Epoch 3/10 30/30 [==============================] - 4s 105ms/step - loss: 0.5606 - accuracy: 0.7078 - val_loss: 0.6208 - val_accuracy: 0.6532 Epoch 4/10 30/30 [==============================] - 3s 93ms/step - loss: 0.5203 - accuracy: 0.7348 - val_loss: 0.6346 - val_accuracy: 0.6518 Epoch 5/10 30/30 [==============================] - 3s 88ms/step - loss: 0.5005 - accuracy: 0.7482 - val_loss: 0.6475 - val_accuracy: 0.6528 Epoch 6/10 30/30 [==============================] - 4s 128ms/step - loss: 0.4894 - accuracy: 0.7507 - val_loss: 0.6617 - val_accuracy: 0.6506 Epoch 7/10 30/30 [==============================] - 3s 93ms/step - loss: 0.4858 - accuracy: 0.7563 - val_loss: 0.6699 - val_accuracy: 0.6465 Epoch 8/10 30/30 [==============================] - 3s 78ms/step - loss: 0.4756 - accuracy: 0.7599 - val_loss: 0.6864 - val_accuracy: 0.6469 Epoch 9/10 30/30 [==============================] - 3s 82ms/step - loss: 0.4719 - accuracy: 0.7629 - val_loss: 0.6984 - val_accuracy: 0.6415 Epoch 10/10 30/30 [==============================] - 4s 118ms/step - loss: 0.4670 - accuracy: 0.7647 - val_loss: 0.6989 - val_accuracy: 0.6417
model.summary()
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
text_vectorization_2 (Text (None, 10) 0
Vectorization)
embedding_1 (Embedding) (None, 10, 16) 512000
global_average_pooling1d ( (None, 16) 0
GlobalAveragePooling1D)
dense_4 (Dense) (None, 256) 4352
dense_5 (Dense) (None, 128) 32896
dense_6 (Dense) (None, 64) 8256
dense_7 (Dense) (None, 1) 65
=================================================================
Total params: 557569 (2.13 MB)
Trainable params: 557569 (2.13 MB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
from matplotlib import pyplot as plt
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'val'], loc='upper left')
plt.show()

plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'val'], loc='upper right')
plt.show()

2.3 Model with Pre-trained Embeddings¶
embedding = "https://tfhub.dev/google/nnlm-en-dim50/2"
hub_layer = hub.KerasLayer(embedding, input_shape=[],
dtype=tf.string, trainable=True)
model = tf.keras.models.Sequential([])
model.add(hub_layer)
model.add(tf.keras.layers.Dense(256, activation='relu'))
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dense(64, activation='relu'))
model.add(tf.keras.layers.Dense(1, activation='sigmoid'))
model.summary()
Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
keras_layer (KerasLayer) (None, 50) 48190600
dense_8 (Dense) (None, 256) 13056
dense_9 (Dense) (None, 128) 32896
dense_10 (Dense) (None, 64) 8256
dense_11 (Dense) (None, 1) 65
=================================================================
Total params: 48244873 (184.04 MB)
Trainable params: 48244873 (184.04 MB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
history = model.fit(train_data.shuffle(10000).batch(512),
epochs=10,
validation_data=validation_data.batch(512),
verbose=1)
Epoch 1/10
/usr/local/lib/python3.10/dist-packages/keras/src/backend.py:5818: UserWarning: "`binary_crossentropy` received `from_logits=True`, but the `output` argument was produced by a Sigmoid activation and thus does not represent logits. Was this intended? output, from_logits = _get_logits(
30/30 [==============================] - 9s 236ms/step - loss: 0.5568 - accuracy: 0.7300 - val_loss: 0.4629 - val_accuracy: 0.7849 Epoch 2/10 30/30 [==============================] - 6s 195ms/step - loss: 0.3504 - accuracy: 0.8473 - val_loss: 0.3545 - val_accuracy: 0.8508 Epoch 3/10 30/30 [==============================] - 6s 201ms/step - loss: 0.2080 - accuracy: 0.9231 - val_loss: 0.3448 - val_accuracy: 0.8621 Epoch 4/10 30/30 [==============================] - 6s 195ms/step - loss: 0.1106 - accuracy: 0.9653 - val_loss: 0.3862 - val_accuracy: 0.8645 Epoch 5/10 30/30 [==============================] - 6s 193ms/step - loss: 0.0471 - accuracy: 0.9887 - val_loss: 0.4697 - val_accuracy: 0.8610 Epoch 6/10 30/30 [==============================] - 6s 209ms/step - loss: 0.0180 - accuracy: 0.9968 - val_loss: 0.5547 - val_accuracy: 0.8628 Epoch 7/10 30/30 [==============================] - 6s 199ms/step - loss: 0.0065 - accuracy: 0.9993 - val_loss: 0.6277 - val_accuracy: 0.8617 Epoch 8/10 30/30 [==============================] - 7s 215ms/step - loss: 0.0031 - accuracy: 0.9996 - val_loss: 0.6809 - val_accuracy: 0.8601 Epoch 9/10 30/30 [==============================] - 6s 185ms/step - loss: 0.0017 - accuracy: 0.9999 - val_loss: 0.7248 - val_accuracy: 0.8592 Epoch 10/10 30/30 [==============================] - 5s 165ms/step - loss: 5.6530e-04 - accuracy: 1.0000 - val_loss: 0.7678 - val_accuracy: 0.8572
from matplotlib import pyplot as plt
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'val'], loc='upper left')
plt.show()

plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'val'], loc='upper right')
plt.show()

2.4 RNN's with the LSTM Layer¶
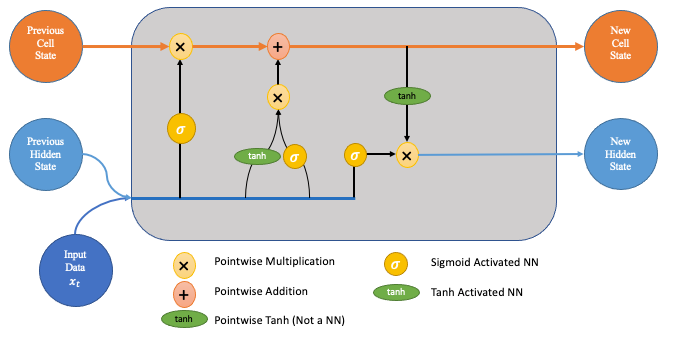
RNN's (Recurrent Neural Networks) are a type of network that can take sequences as input and remember prior parts of the sequence when making predictions.
LSTM layers are a type of recurrent layer that addresses the vanishing gradient problem and allows better memory from prior states.
embedding = "https://tfhub.dev/google/nnlm-en-dim50/2"
hub_layer = hub.KerasLayer(embedding, input_shape=[],
dtype=tf.string, trainable=True)
model = tf.keras.models.Sequential([])
model.add(hub_layer)
model.add(tf.keras.layers.Reshape((50, 1)))
model.add(tf.keras.layers.LSTM(16))
model.add(tf.keras.layers.Dense(16, activation='relu'))
model.add(tf.keras.layers.Dense(1, activation='sigmoid'))
model.summary()
Model: "sequential_5"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
keras_layer_2 (KerasLayer) (None, 50) 48190600
reshape_1 (Reshape) (None, 50, 1) 0
lstm_1 (LSTM) (None, 16) 1152
dense_14 (Dense) (None, 16) 272
dense_15 (Dense) (None, 1) 17
=================================================================
Total params: 48192041 (183.84 MB)
Trainable params: 48192041 (183.84 MB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
model.compile(optimizer=tf.keras.optimizers.Adam(0.0005),
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
history = model.fit(train_data.shuffle(10000).batch(512),
epochs=10,
validation_data=validation_data.batch(512),
verbose=1)
Epoch 1/10 30/30 [==============================] - 9s 216ms/step - loss: 0.6928 - accuracy: 0.5043 - val_loss: 0.6916 - val_accuracy: 0.5512 Epoch 2/10 30/30 [==============================] - 6s 193ms/step - loss: 0.6879 - accuracy: 0.5925 - val_loss: 0.6812 - val_accuracy: 0.6426 Epoch 3/10 30/30 [==============================] - 6s 205ms/step - loss: 0.6622 - accuracy: 0.6781 - val_loss: 0.6318 - val_accuracy: 0.7070 Epoch 4/10 30/30 [==============================] - 6s 195ms/step - loss: 0.5489 - accuracy: 0.7720 - val_loss: 0.4957 - val_accuracy: 0.7904 Epoch 5/10 30/30 [==============================] - 6s 205ms/step - loss: 0.4011 - accuracy: 0.8538 - val_loss: 0.4377 - val_accuracy: 0.8236 Epoch 6/10 30/30 [==============================] - 5s 159ms/step - loss: 0.2919 - accuracy: 0.9005 - val_loss: 0.4013 - val_accuracy: 0.8293 Epoch 7/10 30/30 [==============================] - 6s 197ms/step - loss: 0.2149 - accuracy: 0.9330 - val_loss: 0.4094 - val_accuracy: 0.8427 Epoch 8/10 30/30 [==============================] - 6s 182ms/step - loss: 0.1555 - accuracy: 0.9559 - val_loss: 0.4375 - val_accuracy: 0.8429 Epoch 9/10 30/30 [==============================] - 6s 199ms/step - loss: 0.1173 - accuracy: 0.9711 - val_loss: 0.4656 - val_accuracy: 0.8419 Epoch 10/10 30/30 [==============================] - 7s 221ms/step - loss: 0.0913 - accuracy: 0.9787 - val_loss: 0.4900 - val_accuracy: 0.8416
from matplotlib import pyplot as plt
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'val'], loc='upper left')
plt.show()

plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'val'], loc='upper right')
plt.show()

2.5 Bi-directional LSTM's¶
Bi-directional LSTMs allow information to propagate both forwards and backwards to improve performance.
embedding = "https://tfhub.dev/google/nnlm-en-dim50/2"
hub_layer = hub.KerasLayer(embedding, input_shape=[],
dtype=tf.string, trainable=True)
model = tf.keras.models.Sequential([])
model.add(hub_layer)
model.add(tf.keras.layers.Reshape((50, 1)))
model.add(tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(32, return_sequences = True)))
model.add(tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(16, return_sequences = True)))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(8, activation='relu'))
model.add(tf.keras.layers.Dense(1, activation='sigmoid'))
model.summary()
Model: "sequential_6"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
keras_layer_3 (KerasLayer) (None, 50) 48190600
reshape_2 (Reshape) (None, 50, 1) 0
bidirectional (Bidirection (None, 50, 64) 8704
al)
bidirectional_1 (Bidirecti (None, 50, 32) 10368
onal)
flatten (Flatten) (None, 1600) 0
dense_16 (Dense) (None, 8) 12808
dense_17 (Dense) (None, 1) 9
=================================================================
Total params: 48222489 (183.95 MB)
Trainable params: 48222489 (183.95 MB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
model.compile(optimizer=tf.keras.optimizers.Adam(0.0005),
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
history = model.fit(train_data.shuffle(10000).batch(512),
epochs=10,
validation_data=validation_data.batch(512),
verbose=1)
Epoch 1/10 30/30 [==============================] - 16s 280ms/step - loss: 0.6776 - accuracy: 0.6296 - val_loss: 0.6324 - val_accuracy: 0.6945 Epoch 2/10 30/30 [==============================] - 6s 183ms/step - loss: 0.5371 - accuracy: 0.7417 - val_loss: 0.4750 - val_accuracy: 0.7739 Epoch 3/10 30/30 [==============================] - 7s 218ms/step - loss: 0.3657 - accuracy: 0.8377 - val_loss: 0.4010 - val_accuracy: 0.8190 Epoch 4/10 30/30 [==============================] - 8s 260ms/step - loss: 0.2527 - accuracy: 0.8991 - val_loss: 0.3866 - val_accuracy: 0.8404 Epoch 5/10 30/30 [==============================] - 6s 195ms/step - loss: 0.1735 - accuracy: 0.9369 - val_loss: 0.4058 - val_accuracy: 0.8455 Epoch 6/10 30/30 [==============================] - 5s 176ms/step - loss: 0.1111 - accuracy: 0.9641 - val_loss: 0.4692 - val_accuracy: 0.8467 Epoch 7/10 30/30 [==============================] - 6s 176ms/step - loss: 0.0623 - accuracy: 0.9831 - val_loss: 0.5583 - val_accuracy: 0.8444 Epoch 8/10 30/30 [==============================] - 5s 159ms/step - loss: 0.0345 - accuracy: 0.9923 - val_loss: 0.6550 - val_accuracy: 0.8458 Epoch 9/10 30/30 [==============================] - 5s 175ms/step - loss: 0.0181 - accuracy: 0.9971 - val_loss: 0.7235 - val_accuracy: 0.8436 Epoch 10/10 30/30 [==============================] - 5s 170ms/step - loss: 0.0116 - accuracy: 0.9983 - val_loss: 0.7968 - val_accuracy: 0.8418
from matplotlib import pyplot as plt
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'val'], loc='upper left')
plt.show()

plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'val'], loc='upper right')
plt.show()

max_num_words = 32 * 10**3
vectorize_layer = tf.keras.layers.TextVectorization(
max_tokens=max_num_words,
output_mode='int',
output_sequence_length=10)
vector_size = 50
embedding_layer = tf.keras.layers.Embedding(max_num_words, vector_size)
vectorize_layer.adapt(text_dataset)
model = tf.keras.models.Sequential([])
model.add(vectorize_layer)
model.add(embedding_layer)
model.add(tf.keras.layers.LSTM(16))
model.add(tf.keras.layers.Dense(256, activation='relu'))
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dense(64, activation='relu'))
model.add(tf.keras.layers.Dense(1, activation='sigmoid'))
model.compile(optimizer=tf.keras.optimizers.Adam(0.0005),
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
history = model.fit(train_data.shuffle(10000).batch(512),
epochs=10,
validation_data=validation_data.batch(512),
verbose=1)